With this blog post we want to share insights into how the Platform Engineering team for the Business Marketplace at Deutsche Telekom AG analyzed a Ceph performance issue. Ceph is used for both block storage and object stroage in our cloud production platform.
Background
While the most common IO workload patterns of web applcations were not causing issues on our Ceph clusters, serving databases or other IO demanding applications with high IOPS requirements (with 8K or 4K blocksize) turns out more challenging.
Recently, we got a report from a colleague discussing performance regressions on our Ceph cluster for rados block devices. We were presented results of dd if=/dev/zero of=/dev/vdx bs=1k count=100M.
We were not very happy about getting a report with blocksize of 1k, synthetic sequential writes and /dev/zero as input. But it turned out that even with 4k or 8k, we didn’t get great numbers.
The cluster at that time was dealing fine with 32k and higher blocksizes. But 32k and less indeed resulted in a performance regression compared to an older generation of our Ceph cluster deployment.
Analysis
First we reproduced the issue with fio inside an OpenStack instance with a Cinder-attached RBD, even with pure random write.
Sequential and random reads of the entire RBD were not affected inside the VM.
Also, the average results of rados bench were not perfect but not bad either - lets say they were OK. But not a good indicator if it was a pure Ceph problem or maybe something else within our network.
Initially we spent some time by analyzing with tcpdump and systemtap scripts the traffic librbd was seeing. Indeed we found situations were the sender buffer of the VM host got full while performing 4K random write stress loads inside a guest. (For this we used the example systemtap script: sk_stream_wait_memory.stp)
But this only happened on very intense 4k write loads inside the VM.
Was the IO-pattern sane to tests? Corner case issues?
We decided to look for the right tool to measure detailed latency and IOPS, which is able to reproduce the same load pattern. Bonus point: replaying real-life workloads, that come close to production workload - so we can tune for the right workload (and not for dd bs=4k).
Here started the challenge, since we looking for a tool, that is able to generate the same load on each of the following layers:
- inside the VM guest (to test the RBD QEMU driver, which is using librbd)
- on the VM host (using the same code: librbd. We hesitated to use the RBD kernel module to not miss potential issues inside librbd - if any)
- on the Ceph storage node: testing the ceph-osd code (
FileStoreimplementation. Covering OSD-disk and Journal-disk writes) - on the Ceph storage node: testing the filesystem (XFS) with the used formated options and mount options
- on the Ceph storage node: testing the dmcrypt block device (yep, we do this.)
- on the Ceph storage node: testing the block device directly (through storage/RAID controller. RAID0, write-through)
We would have to use different tools that might produce different workloads, which could lead to different results per test on different layers.
THE right tool: fio
fio was pretty much the perfect match for our cases - it was only missing the capability to talk to Ceph RBD and the Ceph internal FileStore directly.
Fortunately, fio is supporting various IO engines. So we decided to add support for librbd and for the Ceph internal FileStore implementation, to have a artificial OSD processes to benchmark the OSD implementation via fio.
fio librbd ioengine support
With the latest master you can get fio librbd support and test your Ceph RBD cluster with IO patterns of your choice, with nearly all of the fio functionality (some are not supported yet by the RBD engine - not fio’s fault. Patches are welcome!). All you need is to install the librbd development package (e.g. librbd-dev or librbd-dev and dependencies) or have the library and its headers at the designated location.
$ git clone git://git.kernel.dk/fio.git
$ cd fio
$ ./configure
[...]
Rados Block Device engine yes
[...]
$ make
First run with fio with rbd engine
The rbd engine will read ceph.conf from the default location of your Ceph build.
A valid RBD client configuration of ceph.conf is required. Also authentication and key handling needs to be done via ceph.conf.
If ceph -s is working on the designated RBD client (e.g. OpenStack compute node / VM host), the rbd engine is nearly good to go.
One preparation step left: You need to create a test rbd in advance. WARNING: do not use existing RBDs which might hold valuable data!
rbd -p rbd create --size 2048 fio_test
Now one can use the rbd engine job file shipped with fio:
./fio examples/rbd.fio
The example rbd.fio in detail looks like this:
######################################################################
# Example test for the RBD engine.
#
# Runs a 4k random write test agains a RBD via librbd
#
# NOTE: Make sure you have either a RBD named 'fio_test' or change
# the rbdname parameter.
######################################################################
[global]
#logging
#write_iops_log=write_iops_log
#write_bw_log=write_bw_log
#write_lat_log=write_lat_log
ioengine=rbd
clientname=admin
pool=rbd
rbdname=fio_test
invalidate=0 # mandatory
rw=randwrite
bs=4k
[rbd_iodepth32]
iodepth=32
This will perform a 100% random write test across the entire RBD size (will be determined via librbd), as Ceph user admin
using the Ceph pool rbd (default) and the just created and empty RBD fio_test with a 4k blocksize and iodepth of 32 (numbers
of IO requests in flight). The engine is making use of asynchronous IO.
Current implementation limits:
invalidate=0is mandatory for now. The engine just fails without this for now.rbdengine will not cleanup once the test is done. The given RBD is filled up after a complete test run. (We use this to make prefilled tests right now. And recreate the RBD if required.)
Results
Some carefully selected results from one of our development environments while investigating on the actual performance issue.
Following plot shows the original situation we were facing. Result from the fio example RBD job run with a 2GB RBD which was initial empty:
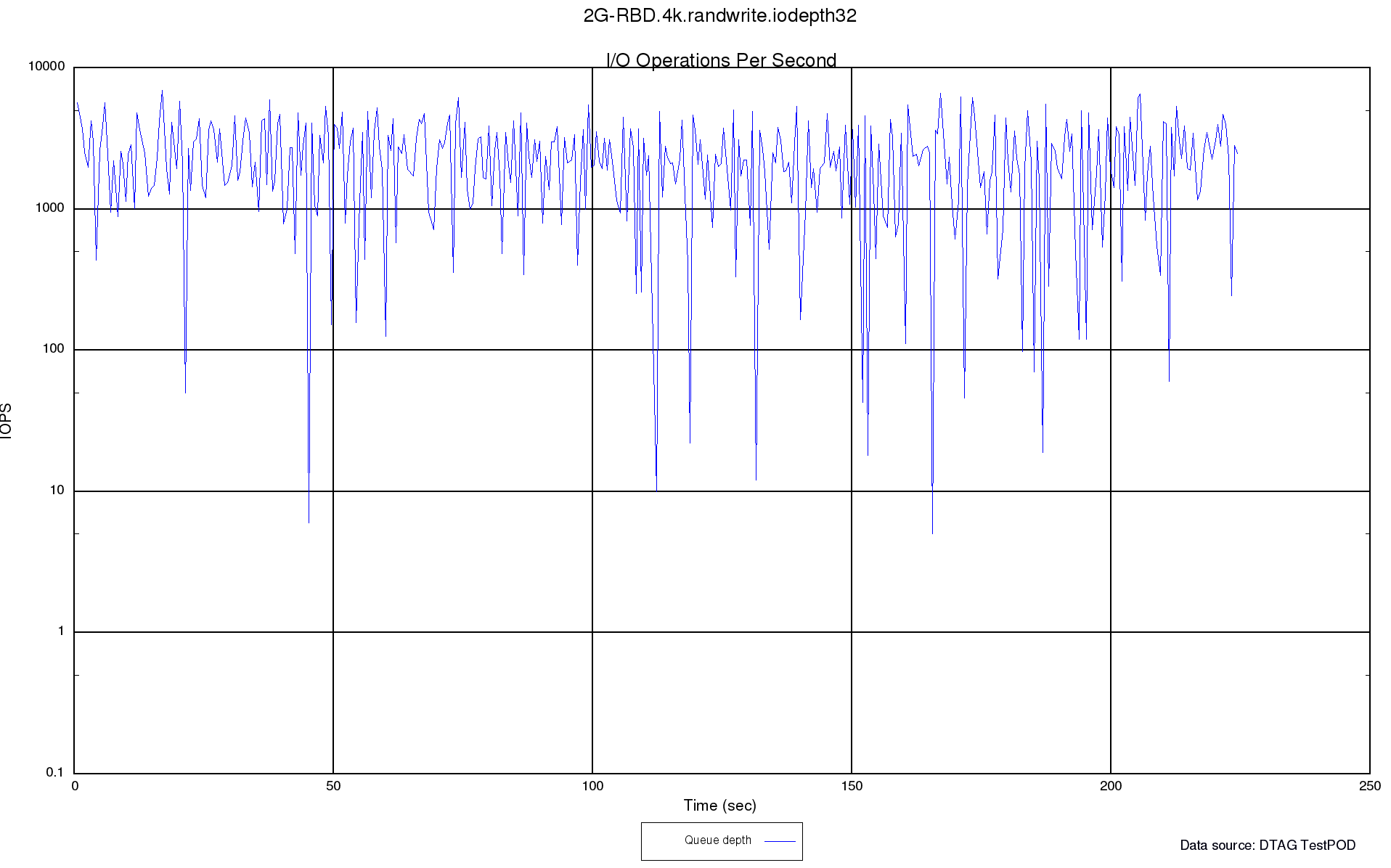
After analysis on the Ceph OSD nodes with fio FileStore implementation and more analysis and tuning we managed to get this result:
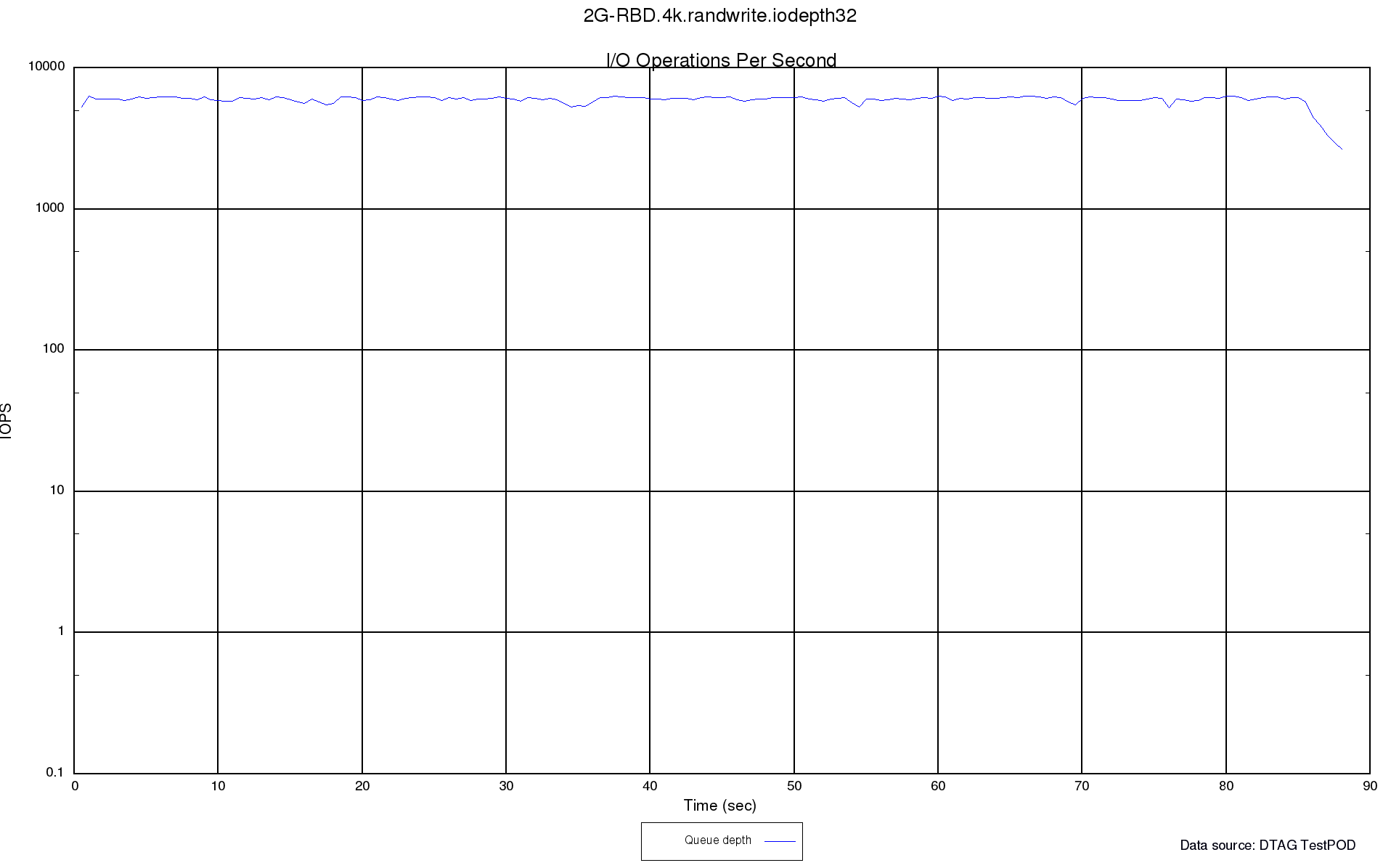
More detailed analysis and result and configuration/setup details will follow with the next postings on the TelekomCloud Blog.
Conclusion
fio is THE flexible IO tester - now even for Ceph RBD tests!
Outlook
We are looking forward to going into more details in the next post on our performance analysis story with our Ceph RBD cluster performance.
In case you are at the Ceph Day tomorrow in Frankfurt, look out for Danny to get some more inside about our efforts arround Ceph and fio here at Deutsche Telekom.
Acknowledgements
First of all, we want to thank Jens Axboe and all fio contributors for this awesome swiss-knife-IO-tool! Secondly, we thank Wolfgang Schulze and his Inktank Service team and Inktank colleagues for their intense support - especially when it turned out pretty early in the analysis, that Ceph was not causing the issue, still they teamed up with us to figure out what was going on.