Getting OpenStack highly available has been a hot topic for us at Deutsche Telekom AG. With the upstream OpenStack High Availability documentation, it’s already well documented how to configure supporting services like MySQL and RabbitMQ in highly available setups.
A challenging area with regards to high availability has been OpenStack Networking. For our OpenStack Grizzly-based cloud, we have made great progress with our solution that we would like to share: how to implement OpenStack Networking (L3 agent) highly available in active/active mode without pacemaker, using traditional routing/balancing functionality.
Our primary goal is to keep VMs available/reachable form the internet with redundant network. I’ll focus on the high-level idea today and post later about the detailed implmentation.
Lets assume we have OpenStack up and running, including OpenStack Networking with Open vSwitch plug-in. The traffic will usually flow from internet -> Network Node -> Open vSwitch -> Full mash GRE tunnel -> Compute node -> Open vSwitch on Compute - >VM:
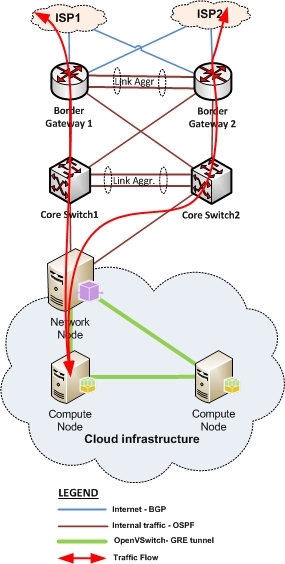
Next, we need a second Network node with Open vSwitch and GRE tunnels to connect to the same Compute nodes:
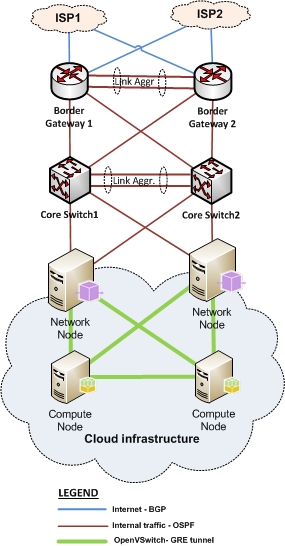
OpenStack Networking gained an important feature in Grizzly, which allow us to schedule to multiple network nodes.
Now we can create a VM on compute node with two nics and assignee two different IP addresses to them. We need to make sure to use IPs that are part of each of the subnets that are mapped to the network nodes / L3 agents.
With this, we have now multiple paths to go out from the VM. In order to avoid any kind of routing problems you need to configure PBR (Policy based routing) insdie the VM. (Details will be provided with the next post.)
The goal is to make sure that packets arriving on interface ethX will be replayed or send back via the same interface. This will require two routing tables and two default routes, one for each interface.
Having done this, we now have multiple paths to the same VM, with different IP addresses.
In case one of network nodes (L3 agents) is not available, the GRE tunnel is not up or for any other reason you cannot access the VM via the first Network node, you can still reach the same VM via the second Network node, but with different IP address.
Finally, we need to set up a load balancer in front of for the Network node to manage the IP swapping, to hide any changes to the IP addresses form the public network.
Summarizing, we now have the networking node working in active/active mode and the traffic will be load-balanced, which also allows us to double the throughput. The traffic flow now looks like this: Internet -> load balancer -> Network node 1 or 2 -> Open vSwitch -> Full mash GRE tunnel -> Compute node -> OpenVswitch -> VM:
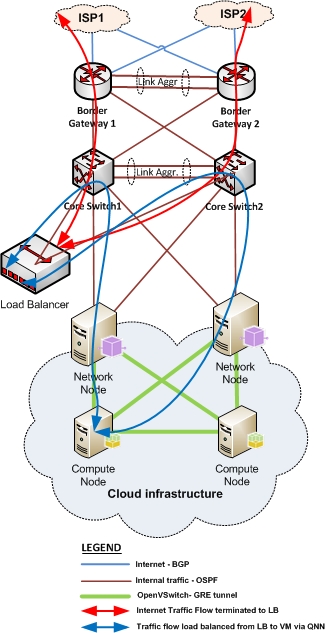
The redundancy of the load balancer is out of scope for this post. You’ll have to choose a load balancer, that best meets your requirements. It could be a hardware appliance, or software based.
In case you don’t want to implement a load balancer in front of the network node, but still want to keep the VM highly availability, you need to take care of the IP address changing yourself. One option would be to use the IP SLA feature of CISCO routers for this. It can monitor the availability of the path to VM and switch to next path with NAT immediately, in case one path is not available:
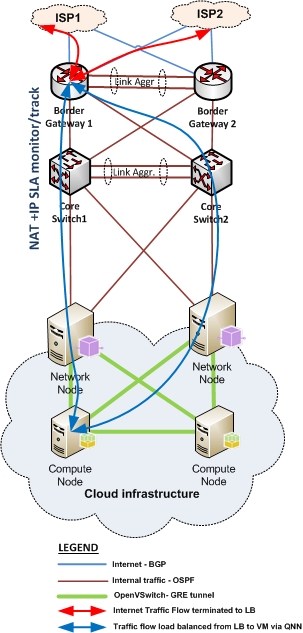
I’m looking forward to your comments and questions!